Azure Data Factory Mapping Data Flows is graphical user interface to build data transformation logic without coding like in SSIS. It generates behind scenes Databricks code (Scala or Python, I’m not sure) and use Databricks cluster to execute jobs.
I think this is the breakthrough feature that cloud data integration has really needed. My first touch to so called ETL tools was about 15 years ago when I started to use Informatica PowerCenter. I was really sold and thought there is no going back to scripting. You can imagine my disappointment when cloud technology started to emerge, but it missed native graphical ETL capabilities. In AWS you have had PaaS ETL services like Talend or Matillion, but you still need to manage your software. AWS has also AWS Glue as a SaaS offering, but I wasn’t convinced at all about that. This ADF Mapping Data Flows is the one I have been waiting for. Real SaaS ETL in the cloud. I have to confess I’m already used to use Databricks Notebooks and coding, but graphical user interface still lowers a barrier for new users a lot.

Note, this is still a preview feature: ”Mapping Data Flow is a new feature of Azure Data Factory. It is currently under limited public preview and is not subject to Azure customer SLA provisions. To sign-up for the preview, please request access here.” GA is waited to be before end of the year. After activation you can see new Factory Resource – ”Data Flows (Preview)”.

You can’t use previously defined datasets. It seems Data Flow uses a little bit different definition format. However you can use precreated Connections.
There are not yet many formats available, but I suppose you could store your source data first in delimeted or parquet format to your blob storage.

In options ”Move” file option I really like after struggling with it quite a lot with ADF. Now they also just recently published new Delete activity into ADF also.

With Data Flow Debug you can view your data and yes, debug your data flow. It spins up a Databricks cluster behind a scene, which takes a moment. I had some challenges with my preview data. I had to my debug mode on, but it didn’t show data, but instructed to start debug mode. It seems that before you click e.g. that source Data Preview tab, you need to start your debug cluster. Otherwise it does not work.

First I used a ”Derived Column” transformation. You can create a new transformation by clicking that small +-sign after previously defined component.
Expression builder is good. Available functions and columns are listed and you can use search. Expression language is quite familiar compared to other products.
A little bit confusing feature is that you need to open expression builder of the previously created column to be able to add new columns.
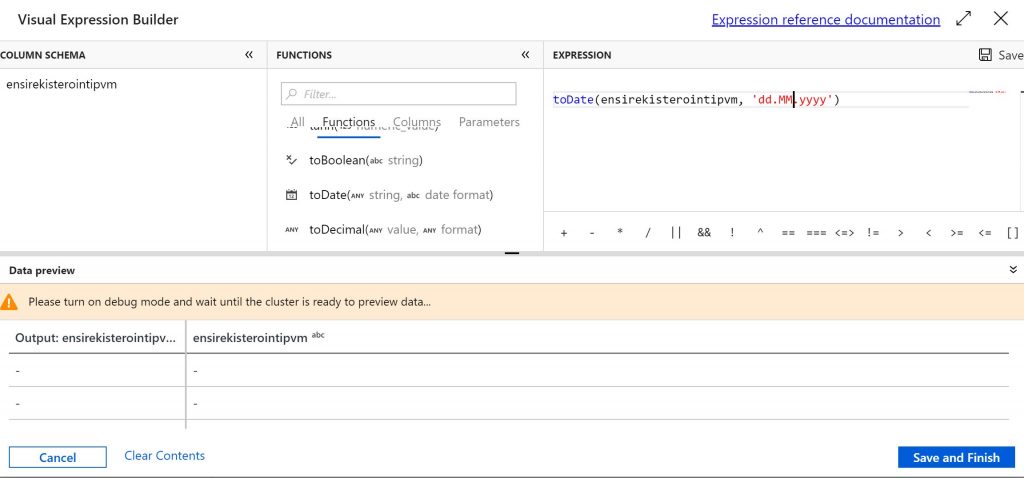
Editor nicely shows if there is an error in expression. In that picture equal since should be with two ==.

Data preview is a nice feature to verify is your code doing what is it suppose to do.

I defined a second source csv-file. I wanted to filter out first three rows, but source definition is missing that possibility. Because of that schema definition was a little bit challenging. You can’t create schema manually, so I had to create a second file without those extra rows and use that as a schema template. Still I had troubles when I used option ”First row as header”. On Data Flow side it showed just nulls. Only when I ticked off header option I managed to get data to my preview. Not totally robust product yet… After that I managed to get rid of additional rows by using filter transformation.


Joiner was easy to create.

Then I created an aggregator to calculate average weight of vehicles per brand and color. That was enough for my testing.

Next was definition of sink. I created the table first into database, but then I noticed that it would be possible to create the table also in the sink definition. Good.
There are also quite many data insert strategies like insert, upsert etc. and you can e.g. truncate sink table before loading.

Source to target mappings were easy to do after disabling ”Auto Mapping” option.

Next challenge was to find out how to execute it. Actually you need to create a pipeline and add your just Data Flow to that pipeline. Source file was 1 GB with few million rows. First execution failed. It claimed one of my column names mapped to sink was wrong. Strange, I selected those from a list and didn’t type those names.

I found out that reason was my upsert rule. Source columns had different names than sink columns. Data Flow requires columns with same names. I changed to insert only mode and everything worked well. Execution took about one minute. Not bad. But I had zero rows in my table :(. I used Debug execution of my pipeline and it apparently uses debug definitions from Data Flow. In other words it loaded only 100 rows and none of those were from year 2016. Next I tried triggering my pipeline. Now it took 10 minutes, but still target table remained empty and source statistics showed 100 rows. Uh…

Next I changed ”Row limit” from my Data Flow Source to empty. I thought that related only to debugging, but not. Now I got DSL Stream parsing error. WTF?

I disabled ”Sampling” from my Data Flow Source. Finally! I got successful execution with rows in the target and it took only 2 minutes.
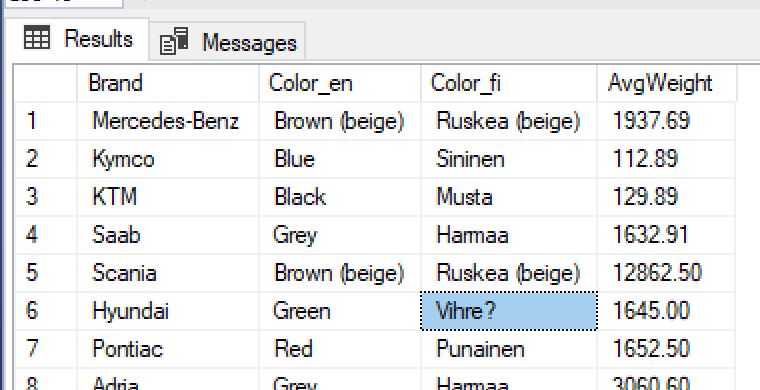
Only thing to complain about results were that scandic letters were incorrect. Check line with color green. It should be ”Vihreä” in Finnish. I tried changing encoding of my file in source definition to UTF-8, ISO-8859-1, Windows-1252, but didn’t help. After that I got tired and decided to do that testing some other day.
Now I know that average weight of green Hyundais sold in Finland in 2016 was 1645 kg. I will make an impression :). I also know that this Azure Data Factory Mapping Data Flows is convincing product with bright future ahead (and I decided to buy some Microsoft shares). If I manage to solve that scandic letter problem, I might start using this product immediately.
I tested scandic letters with database to database connection and there was no problems.
Another note. Data Flows does not yet support Managed Identity or Service Principal authentication to Azure SQL database. So you are left only to SQL authentication.